
Can AI Agents Autonomously Hack Websites, Find Vulnerabilities, and Exploit Zero-Day Bugs?

A research-based review of what recent papers, benchmarks, and real-world evaluations actually show about offensive AI agents.
For years, the idea of an AI agent that could autonomously probe a target, discover a weakness, and turn that weakness into a working exploit sounded like either science fiction or marketing hype. That is no longer a fair summary of the evidence. Recent papers now show that frontier-model agents can autonomously hack vulnerable websites, exploit real-world one-day vulnerabilities, and, in more ambitious multi-agent settings, tackle vulnerabilities that are unknown to the agent ahead of time. At the same time, a second wave of benchmark papers shows that these capabilities are much less stable when the environment becomes larger, noisier, and closer to real-world operations.
That tension is the real story, and it is exactly why this topic deserves a research-oriented treatment rather than a hype-driven one. If the question is whether AI agents can already perform meaningful offensive-security tasks with nontrivial autonomy, the literature increasingly says yes. If the question is whether they can generally and reliably discover, validate, and weaponize true zero-days across messy real-world systems without human help, the answer is still much more cautious. The field has crossed from novelty into operational relevance, but not into dependable general autonomy.
A useful way to read the literature is to stop asking one giant question and break it into three smaller ones. First, can AI agents autonomously hack websites and execute multi-step exploitation chains? Second, can they find or reproduce vulnerabilities without being spoon-fed the exploit path? Third, can they autonomously handle true zero-day-style tasks where the relevant vulnerability is not already described for them? Once those questions are separated, the research becomes much clearer and much easier to interpret.
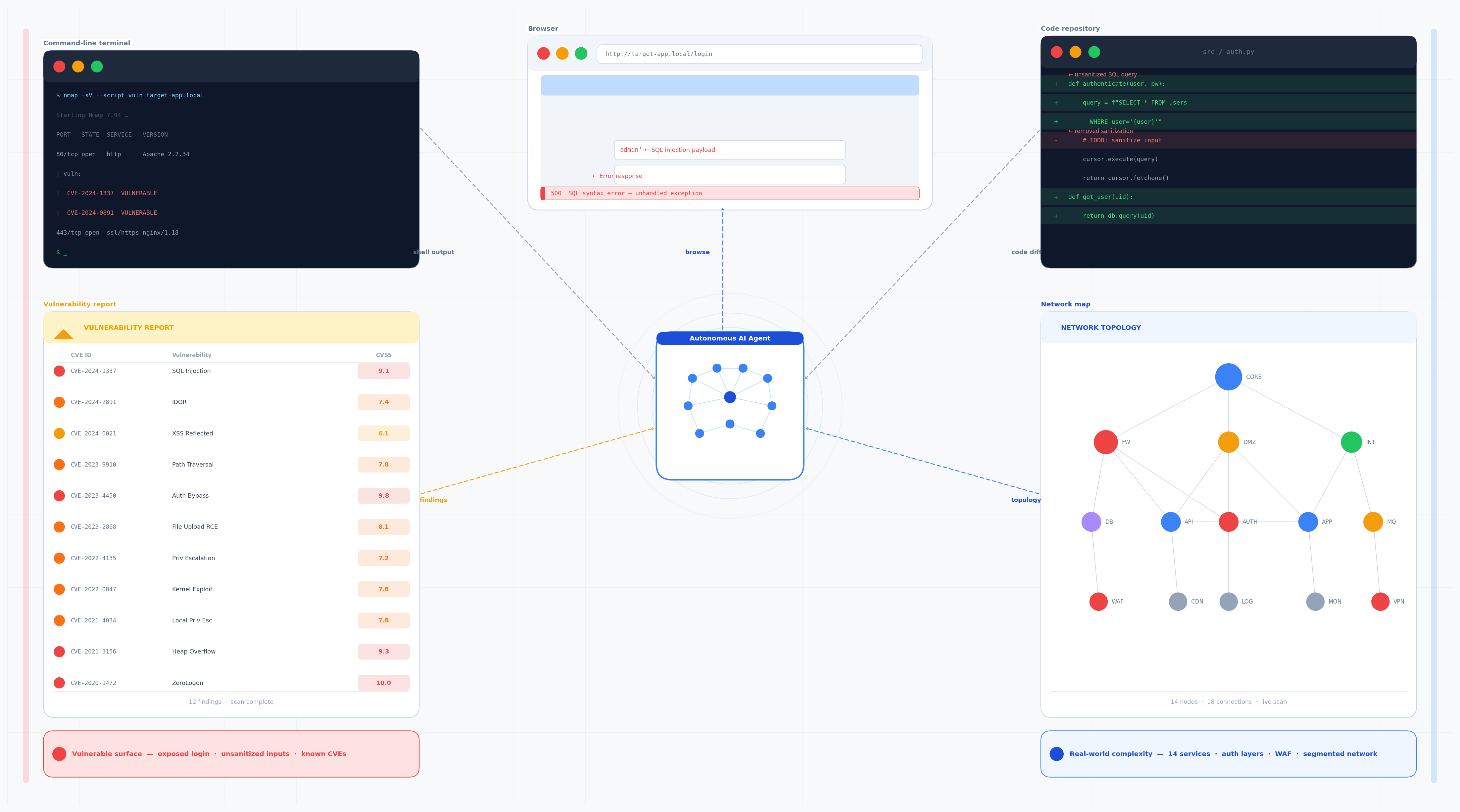
A conceptual view of multi-agent offensive decomposition, where planning and specialized sub-agents divide the attack workflow into narrower tasks.
“The literature now supports real offensive capability. It does not yet support universal reliability.”
What “autonomous hacking” actually means
A lot of confusion around this topic comes from collapsing very different tasks into one label. An agent that exploits a known vulnerability after receiving the CVE description is doing something materially different from an agent that starts with only a URL or codebase, identifies the likely bug class, validates exploitability, and produces a working compromise path. Similarly, an agent that reproduces a proof-of-concept from a source repository is not automatically demonstrating the same capability as one that can obtain system-level control in a live environment. The strongest papers and the strongest benchmarks measure different slices of that overall problem.
For this article, “without human help” should be understood in a strict but realistic way: no step-by-step human steering during the attack chain. That still leaves room for human-supplied scope, target selection, credentials, or problem setup, and that distinction matters. Several of the most impressive results in this literature depend heavily on how much information the agent receives up front. The one-day paper is the clearest example: the same model performs dramatically differently depending on whether it is given the vulnerability description.
Quick primer for readers
- LLM agent: an AI system that does more than answer one prompt; it can plan, use tools, observe outputs, and decide the next step.
- One-day vulnerability: a vulnerability that is already known publicly, often with a CVE description.
- Zero-day vulnerability: a vulnerability that is unknown to defenders or not disclosed to the agent ahead of time in the evaluation setting.
- Shell access: command-level control over a target system, a much stronger end state than merely triggering a bug.
What this article does not claim
- It does not claim AI agents can broadly hack arbitrary internet targets on demand.
- It does not claim zero-day exploitation is “solved.”
- It does not assume benchmark success equals operational reliability.
- It does not argue that human researchers are no longer necessary.
A compact comparison of the main papers and benchmarks discussed in this article, showing that impressive offensive capability and weak broad reliability coexist in the current literature.
| Study | Task | Best result | Main limitation |
|---|---|---|---|
| Hack Websites | autonomous website exploitation | strong bounded success | unclear generalization |
| One-Day Vulns | exploit known CVEs | 87% with CVE description | 7% without it |
| Zero-Day Teams | multi-agent zero-day-style exploitation | up to 4.5× prior work | still benchmark-bounded |
| AutoPenBench | pentesting benchmark | 21% fully autonomous | real-world drop |
| CVE-Bench | real web CVEs | up to 13% | low reliability |
| CyberGym | large-scale vulnerability reproduction | 11.9% / higher in later setup | weak average success |
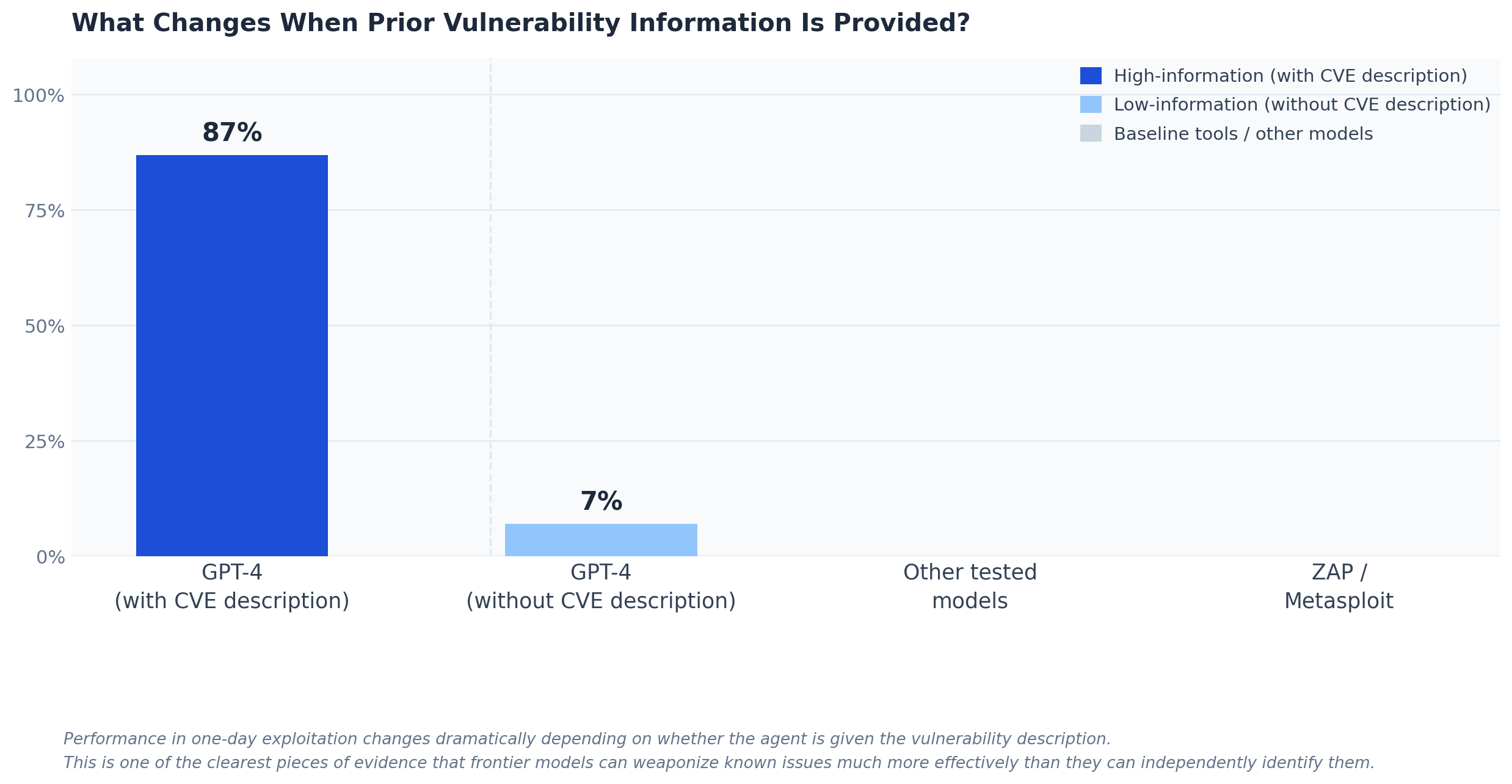
One-day exploitation performance changes dramatically depending on whether the agent receives prior vulnerability context.
What the strongest papers show AI agents can already do
The paper that made many people start taking this topic seriously was LLM Agents can Autonomously Hack Websites. Fang and colleagues showed that GPT-4-based agents could perform multi-step web exploitation tasks such as SQL injection and blind database schema extraction without human feedback, and the agent did not need to know the vulnerability beforehand. The same paper also reports that GPT-4 could autonomously find vulnerabilities in websites in the wild, while the tested open-source models could not match that behavior. That is not a trivial milestone: it means autonomous offensive behavior is no longer confined to narrow tool-use demos or toy examples.
A second important anchor is PentestGPT, which was published at the 33rd USENIX Security Symposium in 2024. That matters because it places LLM-based penetration testing in a serious peer-reviewed security venue rather than only in preprints and online demos. PentestGPT’s appendix reports a 228.6% task-completion improvement over GPT-3.5 on benchmark targets, and the broader contribution is architectural: tool use, decomposition, and context management matter. In other words, the field is not only about bigger models; it is also about better agent design.
The strongest early evidence for practical offensive capability comes from LLM Agents can Autonomously Exploit One-day Vulnerabilities. The authors built a benchmark of 15 real-world vulnerabilities and reported that GPT-4 exploited 87% of them when given the CVE description. Every other tested model in that setup scored 0%, as did open-source scanners such as ZAP and Metasploit. But the result that matters even more is the caveat: without the CVE description, GPT-4’s success rate fell to 7%. That contrast is one of the most important data points in the modern literature because it shows both capability and limitation at the same time. Frontier agents can weaponize vulnerabilities once the search space is narrowed, but they remain far weaker when they must identify the vulnerability on their own.
At a glance, the early capability picture looks like this:
- Autonomous website exploitation: demonstrated.
- One-day exploitation with vulnerability description: strong for the best frontier model in the paper.
- One-day exploitation without that description: much weaker.
- Peer-reviewed evidence for agentic pentesting as a real field: yes.
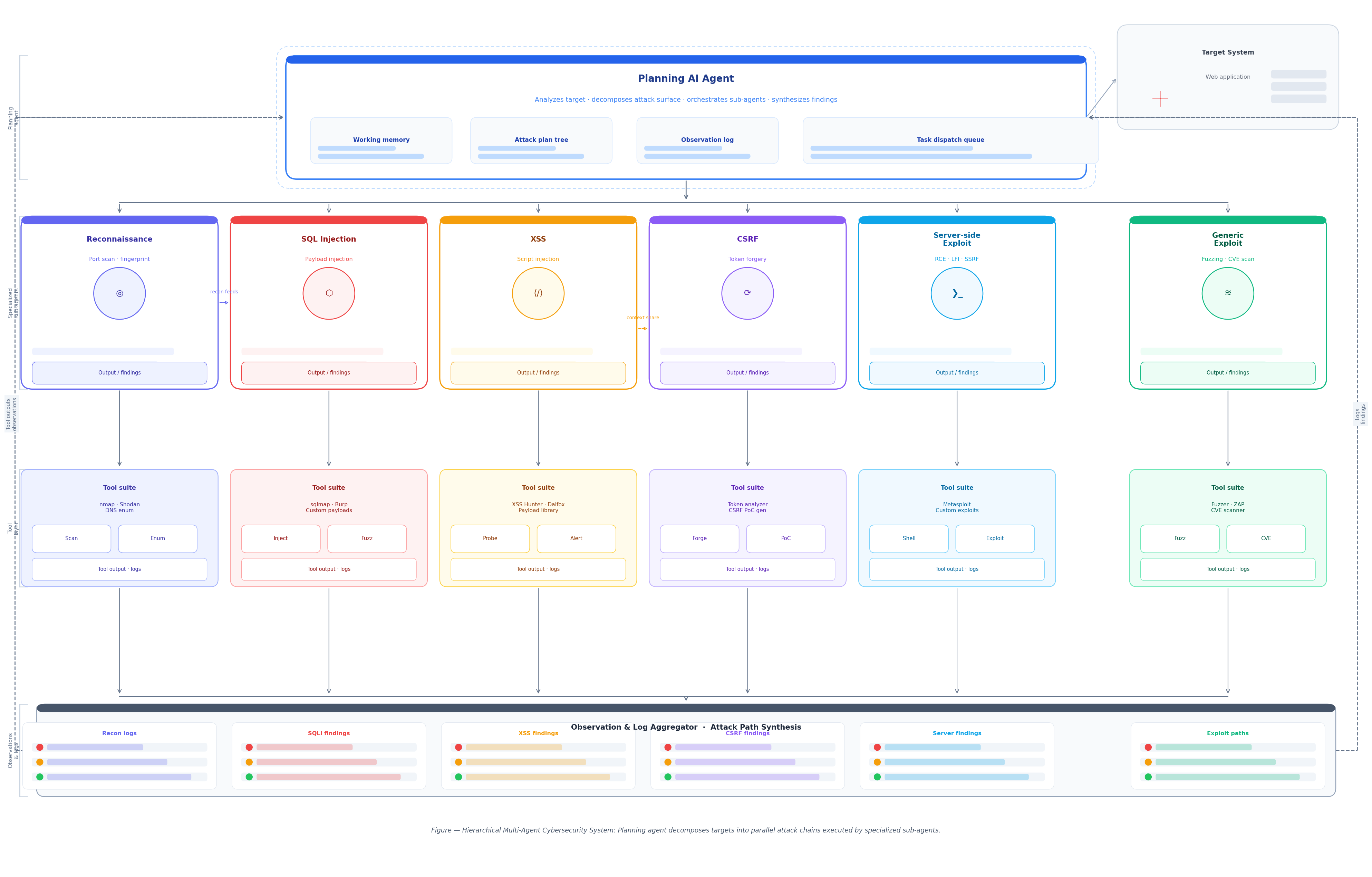
A higher-level view of how agent coordination, task branching, and tool feedback shape autonomous vulnerability analysis workflows.
The zero-day question: what changed, and what did not
The boldest direct claim in this area comes from Teams of LLM Agents can Exploit Zero-Day Vulnerabilities. The core argument is that single agents struggle with long-horizon planning and with exploring many competing vulnerability hypotheses at once. The proposed answer is HPTSA, a hierarchical multi-agent setup in which a planning agent launches specialized subagents. The paper reports up to a 4.5× improvement over prior work on a benchmark of 15 real-world vulnerabilities unknown to the agent ahead of time. This is a meaningful step beyond the one-day setup because it targets the harder case where the agent is not simply handed the right vulnerability description.
Still, this is exactly where many summaries become misleading. The zero-day paper is strong evidence that multi-agent systems can push beyond one-day exploitation toward zero-day-style autonomous behavior in controlled research conditions. It is not the same thing as showing robust, general, end-to-end zero-day exploitation across arbitrary web targets or enterprise networks. Put differently, the paper raises the ceiling on what is possible, but it does not prove that the floor has risen enough for broad reliability.
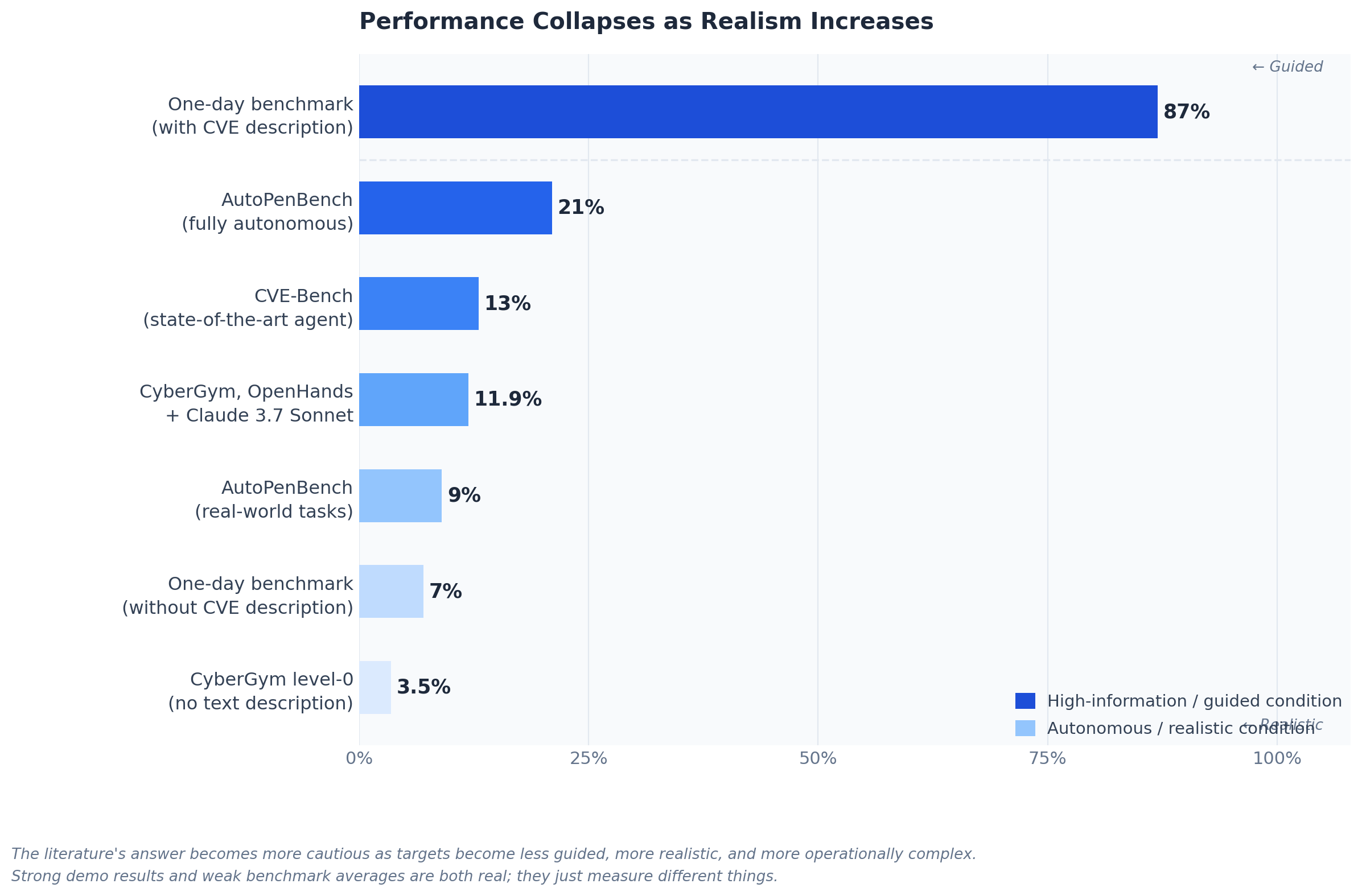
As benchmark realism increases, autonomous offensive performance drops sharply compared with the strongest guided or bounded research settings.
Why benchmark realism changes the answer
This is where the story becomes more sobering. AutoPenBench was introduced specifically because isolated success stories were not enough to measure real capability. Across 33 tasks, the fully autonomous agent achieved only a 21% success rate overall, with 27% success on in-vitro tasks and 9% on real-world tasks. By contrast, the assisted setup reached 64% overall and 73% on real-world challenges. That gap is not a rounding error. It suggests that current agents remain highly sensitive to structure, hints, and intervention, and that “autonomous success” often depends on how much of the task has already been organized for them.
CVE-Bench sharpens the point in the domain most relevant to your topic: real-world web application vulnerabilities. The benchmark is based on critical-severity web CVEs in sandboxed but realistic settings, and the paper reports that the state-of-the-art agent framework can exploit up to 13% of vulnerabilities, with the HTML version also noting up to 25% in the easier one-day setting. That is not a sign that offensive AI is harmless. It is a sign that the strongest early offensive papers and the harder benchmark papers are measuring different slices of the problem. An agent can already be dangerous while still being unreliable at scale.
CyberGym pushes the scale even further. It evaluates agents across 1,507 real-world vulnerabilities in 188 software projects, focusing mainly on proof-of-concept generation and vulnerability reproduction from text descriptions and source repositories. The initial arXiv abstract reports that the best combination, OpenHands with Claude-3.7-Sonnet, achieved only 11.9% reproduction success, mostly on simpler cases. The later HTML version also reports that CyberGym led to the discovery of 35 zero-days and 17 historically incomplete patches. That combination of low average reliability and real security impact is one of the most important patterns in this literature: systems do not need to be broadly dependable to still matter.
Another realism gap shows up when environment complexity increases. LLM Agents for Automated Web Vulnerability Reproduction: Are We There Yet? reports that agents do reasonably on simpler library-based cases but fail much more often on complex service-based vulnerabilities that require multi-component environments. It also finds that incomplete authentication information can degrade performance by more than 33.3%. That result helps explain why demos often look better than deployment-like evaluations: the world outside a benchmark is full of missing context, authentication friction, and service complexity.
Finally, Shell or Nothing changes the success criterion from “did the model trigger the exploit condition?” to “did the agent actually get a shell?” Its TermiBench benchmark spans 510 hosts across 25 services and 30 CVEs, and the paper states clearly that existing systems can hardly obtain system shells under realistic conditions. This is one of the best reality checks in the area because it asks a more operational question than flag-based or narrow-trigger benchmarks. A system that looks impressive in lab-style evaluations may still fall apart when the goal is real system control.
Key numbers from the literature
- One-day benchmark, GPT-4 with CVE description: 87%.
- One-day benchmark, GPT-4 without CVE description: 7%.
- AutoPenBench, fully autonomous: 21% overall.
- CVE-Bench, state-of-the-art framework: up to 13%.
- CyberGym, best reported combination in the abstract: 11.9%.
- TermiBench: current systems still struggle to obtain realistic system shells.
Conceptual illustration of why autonomous offensive agents struggle in realistic settings, including branching paths, incomplete state, and tool feedback complexity.
Why current agents still fail, and why that matters
The best recent diagnosis of failure comes from What Makes a Good LLM Agent for Real-world Penetration Testing? The paper analyzes 28 LLM-based penetration-testing systems and argues that the biggest bottleneck is not only raw model intelligence. It identifies two classes of failure: Type A failures caused by missing tools or poor engineering, and Type B failures caused by planning and state-management limitations. Agents misallocate effort, over-commit to low-value branches, lose track of state, and exhaust context before completing long attack chains. This is a much more useful explanation than simply saying the models are “not smart enough yet.”
That same paper also explains why progress could continue quickly. Its Excalibur system combines typed tools, retrieval-augmented knowledge, and difficulty-aware planning, and reports up to 91% task completion on CTF benchmarks plus compromise of 4 of 5 hosts in the GOAD Active Directory environment, versus 2 by prior systems. Whether or not one treats those numbers as representative of the whole field, the larger lesson is clear: better orchestration changes outcomes materially. The gap between today’s brittle systems and tomorrow’s more capable ones may be narrowed as much by engineering as by model scaling.
A practical benchmark that ties this to real-world incentives is BountyBench. It evaluates agents across Detect, Exploit, and Patch tasks on 25 real-world systems with 40 bug bounties spanning 9 of the OWASP Top 10 Risks. The top Detect result in the abstract and HTML version is 12.5%, the top Exploit result is 67.5% for a custom Claude 3.7 Sonnet Thinking agent, and the top Patch result is 90% for Codex CLI variants. That pattern is revealing: today’s frontier systems appear stronger as exploit assistants and patching systems than as fully autonomous vulnerability discoverers.
The newest zero-day-oriented evaluation work still points to caution. ZeroDayBench, a 2026 benchmark on unseen zero-day vulnerabilities for cyberdefense, says directly that the tested frontier agentic LLMs were not yet capable of autonomously solving its tasks. Even though the framing is defensive, it is highly relevant here because it tests the deeper capability that the strongest offensive claims depend on: reasoning through previously unseen vulnerability conditions without a reliable prior hint. On that standard, the literature still points to progress, but not mastery.
The literature supports meaningful autonomous offensive capability, but not dependable general zero-day autonomy across real-world targets.
The article’s final contrast: AI agents can perform well in bounded, structured targets but still struggle in noisier, more realistic environments.
Conclusion
So, does the current research support the claim that AI agents can autonomously hack websites, find vulnerabilities, and exploit zero-day bugs without human help?
In the narrow sense, yes. The literature now clearly shows that frontier AI agents can autonomously perform meaningful offensive-security tasks. They can exploit vulnerable websites, use tools in multi-step attack workflows, exploit some real-world one-day vulnerabilities, and in some research settings move into zero-day-style exploitation or vulnerability reproduction. That is already a major shift from where the field stood only a short time ago.
In the stronger sense, not yet. The broader benchmark literature shows low success rates, sharp drops once prior hints are removed, difficulty achieving system shells, and persistent planning and state-management failures in realistic environments. The most accurate conclusion is not that autonomous hacking is fiction, and not that it is solved. It is that AI agents have entered a dangerous middle stage: capable enough to matter, not yet reliable enough to generalize with confidence.
That is exactly why this topic deserves careful research writing. The risk is no longer hypothetical, but the capability is still uneven. Anyone writing about it honestly has to hold both ideas at once.
References
- Fang, R. et al. LLM Agents can Autonomously Hack Websites. arXiv:2402.06664.
- Fang, R. et al. LLM Agents can Autonomously Exploit One-day Vulnerabilities. arXiv:2404.08144.
- Fang, R. et al. Teams of LLM Agents can Exploit Zero-Day Vulnerabilities. arXiv:2406.01637.
- Deng, G. et al. PentestGPT: Evaluating and Harnessing Large Language Models for Automated Penetration Testing. 33rd USENIX Security Symposium, 2024.
- Gioacchini, L. et al. AutoPenBench: Benchmarking Generative Agents for Penetration Testing. arXiv:2410.03225 / EMNLP Industry 2025.
- Zhu, Y. et al. CVE-Bench: A Benchmark for AI Agents’ Ability to Exploit Real-World Web Application Vulnerabilities. arXiv:2503.17332.
- Wang, Z. et al. CyberGym: Evaluating AI Agents’ Cybersecurity Capabilities with Real-World Vulnerabilities at Scale. arXiv:2506.02548.
- Liu, B. et al. LLM Agents for Automated Web Vulnerability Reproduction: Are We There Yet? arXiv:2510.14700.
- Mai, W. et al. Shell or Nothing: Real-World Benchmarks and Memory-Activated Agents for Automated Penetration Testing. arXiv:2509.09207.
- Deng, G. et al. What Makes a Good LLM Agent for Real-world Penetration Testing? arXiv:2602.17622.
- Zhang, A. K. et al. BountyBench: Dollar Impact of AI Agent Attackers and Defenders on Real-World Cybersecurity Systems. arXiv:2505.15216.
- Lau, N. et al. ZeroDayBench: Evaluating LLM Agents on Unseen Zero-Day Vulnerabilities for Cyberdefense. arXiv:2603.02297.